
Helping the customer help himself is undoubtfully one of the most important things you can do in Customer Support. For this you need two things:
Have a great knowledge base that includes clear answers to many of the customers’ questions.
Help the customer find the answer he or she needs before reaching out to the Support team.
These are the two sides of the same coin, both equally important.
In this issue, I will focus on number two: helping customers find the right answers in the knowledge base.
More precisely, I will describe how I used OpenAI’s GPT-3 to build a ticket deflection system that works out of the box: it doesn’t require prior training and constant fine-tuning.
GPT-3 is a new AI natural language model from OpenAI, currently available in private beta to developers as a cloud API service. If you’re not familiar with it, I suggest you check out this intro article and my previous issue describing some Customer Support use cases achievable with GPT-3.
Thoughts on existing AI ticket deflection tools
Let’s start by looking at the existing methods that help customers find the right answers in a knowledge base before contacting Support.
AI advancements in recent years paved the way to a new kind of tools. These tools can be plugged into existing support channels, capture what the customer query is, detect the customer intent and suggest relevant articles or FAQs mapped to that intent.
Currently, such a tool requires a significant effort to set up and maintain. Reason: the AI technology behind these tools rely on supervised machine learning methods.
Translated in English, it means you (or your vendor) need to build and maintain a large library of intents, with one intent for each possible customer question that could be answered with an article. For each intent, you need to add and maintain a long list of sentences and text snippets your customers use to phrase the same question.
Let’s take an example from eCommerce. You want your AI to “understand” when customers are asking whether you ship products to a particular location, and suggest them an article answering their question. For that, you need to train the AI with many example phrases of this question, such as:
“Do you deliver to Ireland?”
“Where do you ship?”
“Would you post iPhone to France?”
“Can I order from Italy?”
And it’s not just the initial heavy lifting. You need to keep tuning this intent for months after launch, to ensure related customer questions are correctly understood and answered. It might not seem hard for one intent, but imagine doing this for 50 intents, or more.
Check out my article on AI automation for a detailed explanation on how supervised machine learning works.
Searching by meaning, not keywords, with semantic search
An alternative to supervised learning is search: use the customer question to turn it into a query and perform a keyword search on your knowledge base. The problem is, the words your customers use to describe a problem are not always the same as the words used in your knowledge base. Enter semantic search!
Semantic search has been around for a while. It is powering a good part of Google searches and some high-end tools available in the enterprise search market. Usually very expensive, inaccessible to small and medium support teams.
So what is semantic search? It is searching by meaning, instead of keywords.
Let’s take a very simple example. If you search on google “Who is the wisest avenger?”, this is what you get:

Note that none of the sentences in the response contains the word “wise”. But Google just “knows” that the question is the same as asking about the “smartest avenger”. You search by meaning, not keywords.
Fortunately, semantic search powered by GPT-3 is one of the features offered by OpenAI to developers. It still has a few limitations but is getting closer to a production-ready service.
So how to use semantic search to help a customer find his answer into the knowledge base?
Let’s take an example. The customer is asking this question:
“Can I order from Italy?”
From a long list of FAQs, you need to pick the one that is the closest in meaning to the actual question. Your FAQ titles will probably have phrases that include the word “order”, such as: “Where is my order?”, “I want to cancel my order”, or “I didn’t receive my order on time”. Therefore simply searching for the word “order” won’t help.
I used GPT-3 to do a semantic search for the above question on a list of eCommerce FAQ titles and find the one that is closest in meaning.
This is the list of results sorted by relevance:
“Where do you ship?”
“Where is my order?”
“I want to cancel my order”
“I didn’t receive my order on time”
As you can see, GPT-3 is able to correctly identify the closest phrase to “Can I order from Italy?” as being “Where do you ship?”, even if there are no common words between the two sentences. This is semantic search!
Off the shelf ticket deflection app
Excited by the results above, I decided to build a pilot app that scans a public-facing help center and returns the most relevant answers to a given customer question or problem.
Note that I wrote “answers” and not “articles”. One article can answer multiple customer questions and simply giving the customer a link to the article might not be enough. Also, turning your entire help center into a list of FAQs is probably not feasible.
For illustration purpose, I used the app to scrape the Mailchimp’s help center, detect automatically the different sections within each article and save each section into smaller “knowledge cards”. Below is an example of such a card. It includes a small section from an article on troubleshooting activation emails.

Then I used GPT-3 to take a given customer query, perform a semantic search on all the knowledge cards and find the most likely card that answers the query. Let’s see what the app returns with two examples.
The first customer query is: “I was banned for no reason at all. My entire account was deleted and I lost all of my content”
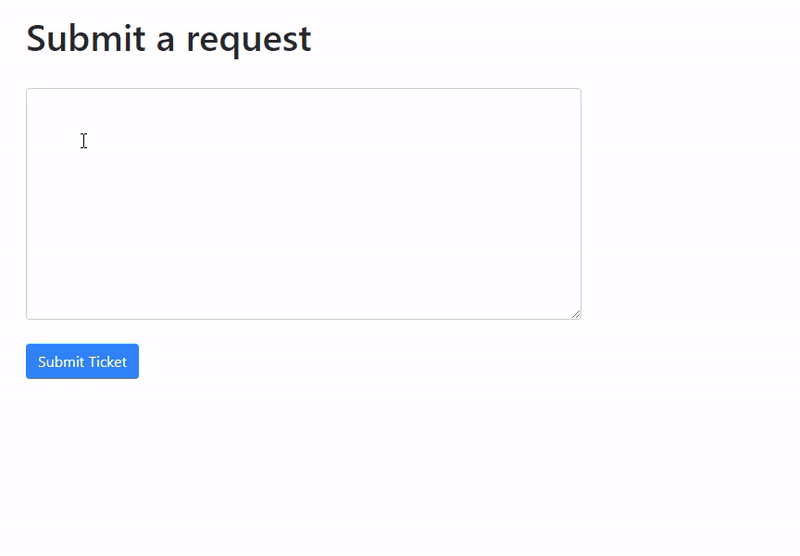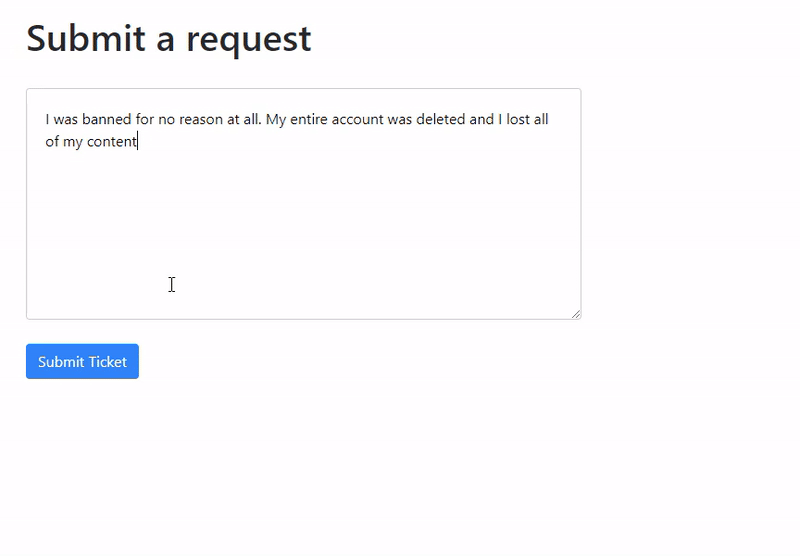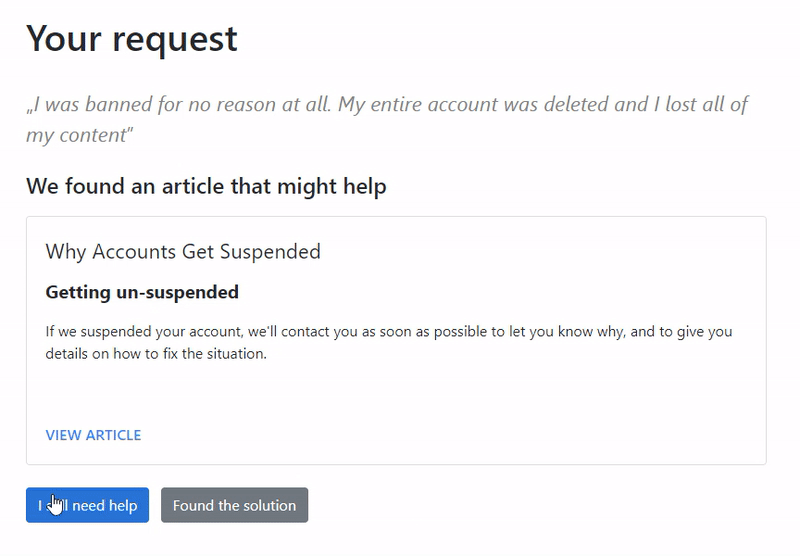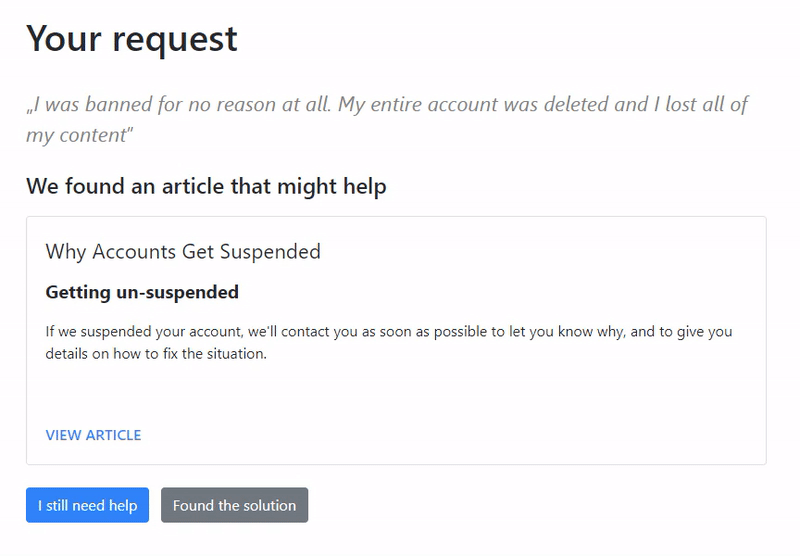
The app surfaced the correct section on suspended accounts, even though the word “banned” used by the customer is not present in the article section.
For the second example, the customer query is: “I tried to add a new user but he didn’t get the email”

Same here, using semantic search the app correctly identifies the section on “troubleshooting a user invite” as being the “closest” to the phrase customer used to mention the problem.
Of course, there are some examples for which the app doesn’t return the correct response, but most of the time it was able to identify a close solution to my test queries.
Even when the customer phrases his question using different terms than those used in the knowledge base, with semantic search the app could still find the right answer.
Why use semantic search
To conclude, there are several advantages in using semantic search for ticket deflection.
It works out of the box. You don’t need to build and maintain a large library of intents and customer phrases, which can go on over weeks if not months.
There are no privacy concerns or data protection issues. It only needs access to your help center, which is already public. On the other hand, to train an AI model with intents (supervised learning), you need thousands of text snippets exported from customer tickets. This can be a cause of concern as support tickets usually contain sensitive customer information.
There are some disadvantages as well. You can’t improve it if you need to. Also, it might not be accurate enough when the domain language is highly specialized. For this reason, I don’t expect it would work as good as a supervised model with intents trained very well over many weeks or months. But I believe there is a trade-off between the time spent working hard on improving a model and the benefit you’re getting in terms of deflection.
The future of AI is zero-shot (or few-shot)
Ticket or chat deflection has been one of the most used applications of AI in Customer Support. There are many tools and vendors providing solutions in this area, but they require a significant amount of effort to implement. The reason for that is because custom AI models still need a large number of examples to be trained on.
This is changing. Latest natural language models such as GPT-3 only need few or even no examples to learn from. They pick up the patterns in data much faster without needing thousands of training data points. This is the reason I believe the future of AI is zero or few-shot learning.